Team Teaching - Fault Tolerance & Parallel and Distributed Computing
College Board 4.2 & 4.3 - Fault Tolerance & Parallel and Distributed Computing
Fault Tolerance
Fault Tolerance: The ability of a system to continue to operate properly and without interruption if one or more of its components were to fail.
There are a few factors you need to confirm to decide if a system is fault tolerant or not. Think of each device/point as a pool, and the lines as pipes.
-
If you were to pour water into any pool, can the other pools access the water? (can data be accessed from all points?)
-
If one pipe were to be cut, can the other pools still access the water? (If a path fails, can data be accessed from all points?)
-
If one pool is removed, can the other pools still access water from eachother? (If one device fails, can the other points receive data?)
If to answer to all of these are “Yes,” then the system is Fault Tolerant.
Redundancy: Fault Tolerant networks typically have extra components and pathways to ensure reliability, making them have redundancy.
“Essential Knowledges” from College Board
-
The Internet has been engineered to be fault-tolerant, with abstractions for routing and transmitting data.
-
Redundancy is the inclusion of extra components that can be used to mitigate failure of a system if other components fail.
-
One way to accomplish network redunadancy is by having more than one path between any to connected devices.
-
If a particular device or connection on the Internet fails, subsequent data will be sent via a different route if it’s possible to reach that.
-
Redundancy within a system often requires additional resources but can provide the benefit of fault tolerance.
-
The redundancy of routing options between 2 points increases the reliability of the Internet and helps it scale to the more devices and more people.
Examples:

- The network above is not fault tolerant because if one path stops working, data cannot be accessed by further devices.

- The network above is fault tolerant since if one path stops working, you are still able to communicate with all the other devices on the network.

- The network above is also fault tolerant due to the same reasons as the previous example. The network is much more redundant, meaning it is more Fault Tolerant. However, it will require more resources. more components = more expensive.
Popcorn Hack #1 (True or False)
- Identify if the network above is Fault Tolerant or not, and why.
Answer here: false
What are the benefits of having a Fault Tolerant Network?
-
Data has more than one path to travel from one device to another.
-
If part of the network fails, the network can still function by using other paths.
-
More devices creates more connections and makes the network stronger.
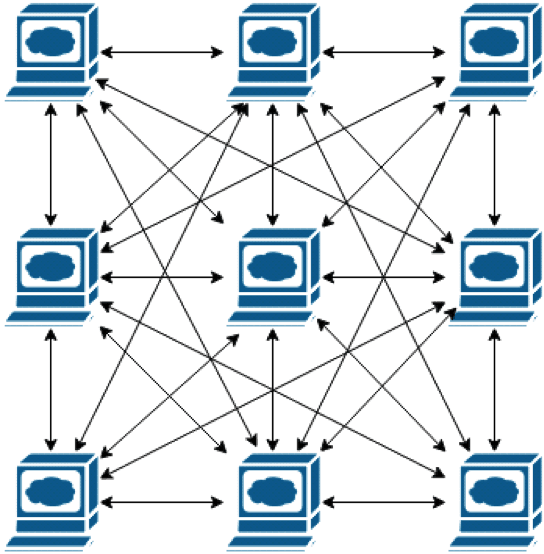
Popcorn Hack #2 (Multiple Choice)
Is this network above Fault Tolerant? If not, what changes can you make that can make this a fault tolerant network?
- A: connection from *A ---> B*
- B: connection from *B ---> D*
- C: connection from *E ---> F*
- D: connection from *B ---> C*
Answer here: A
Parallel and Distributed Computing
Computer Tasks: All of the tasks that are operated on the computer has to be handled by the computer. These tasks are scheduled by the operating system.
-
System tasks: Tasks that are done for the operating system, such as managing hardware, network configuration, file management, and security tasks.
-
User tasks: Tasks that the user themself has selected, such as running a search engine, opening a video game, and running MS paint.
Because computers have many tasks to manage, they need to balance the tasks so all CPUs are being utilized evenly and fully.
Sequential Computing: Tasks are done one after the other; operations are performed one at a time.
-
Not efficien. A computer would use sequential computing if its hardware is limited, or if the tasks requested are dependent on eachother.
-
Useful because it requires less resources and is easier to manage, and has a lower chance of error compared to parallel computing.
-
Takes long for computer to execute all tasks. If Task X takes 30 ms, Y takes 40 ms, and Z 20 ms, and the order executed is X-Y-Z, then the total processing time is 90 ms.
Parallel Computing: tasks are done simultaneously.
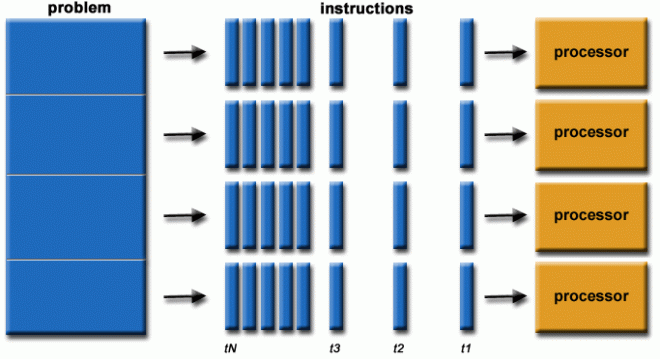
-
Hardware Driven: newer hardwares have several processers in one system called cores. One CPU can have 64+ cores. This speeds up the processing time greatly.
-
Faster Operations: links CPUs together to work the same problem.
-
Data Driven: Data can be processed the same way called Single Instruction Multiple Data.
-
Processing time is the longest time taken for the procressors. Example Core 1 takes 50 ms, Core 2 100 ms, Core 3 10 ms, total time taken is 100 ms. This is why parallel processing works best when tasks are independent from eachother.
Speedup Time: The speedup of a parallel solution is measured in the time it takes to complete the task sequentially divided by the time it takes to complete the task in parallel. Example Sequential time is 120 ms, parallel time is 60 ms, speedup time is 2 ms
Distributed Computing: sending of tasks from one computer to another; multiple devices are used to run a program. Requires a network.

-
Can mix sequential and parallel computing, based on how it sends out tasks to other computers to work.
-
Allows problems to be solved that aren’t possible on a single computer due to storage limitations and processing time.
For example, when you search something up on google, Google sends the request to thousands of servers in the backround for your answers.
Web Services: Standards on how computers can ask for tast execution over the web, including protocols
Beowolf Clusters: special software grouping different computers together
Essential Knowledges from College Board:
-
Sequential computing is a computational model in which operations are performed in order one at a time.
-
Parallel computing is a computational moder where the program is broken into multiple smaller sequential computing operations, some of which are performed simultaneously.
-
Distributed computing is a computational model in which multiple devices are used to run a program.
-
Comparing efficiency of solutions can be done by comparing the time it takes them to perform the same task.
-
A sequential solution takes as longas the sum of all its steps.
-
A parallel computing solution takes as long as its sequential tasks plus the longest of its parallel tasks.
-
The “speedup” of a parallel solution is measured in the time it took to complete the task sequentially divided by the time it took to complete the task when done in parallel.
-
Parallel computing consists of a parallel portion and a sequential portion.
-
Solutions that use parallel computing can scale more effectively than solutions that use sequential computing.
-
Distributed computing allows problems to be sovled that ould not be solved in a single computer because of either the processing time or the stroage needs involved.
-
Distributed computing allows much larger problems to be solved quicker than they could be solved using a single computer.
-
When increasing the use of parallel computing in a solution, the efficiency of the solution is still limited by the sequential portion. This means that at some point, adding parallel portions will no longer meaningfully increase efficiency.
Popcorn Hack #3
Explain the difference between Sequential, Parallel, and Distributive computing in 1-2 sentences. Try to not look at answers above, and put it in your own words.
Sequential computing refers to a traditional approach where tasks are executed one after another, in a linear fashion, while parallel computing involves executing multiple tasks simultaneously using multiple processing units, and distributive computing involves dividing a task into smaller subtasks that are executed on different machines or processors in a networked environment.
HOMEWORK
Fault Tolerance:
Make two data flowcharts like the examples above, you can use MS paint, canva, any design website. Make one Fault Tolerant and one not fault tolerant, and explain what needs to be changed to the flowchart in order to make the network fault tolerant. Doing these will get you over a .90:
- Neat design, easy to understand
- real network examples; don’t label each point as A-B-C etc.
Parallel and Distributed Computing:
- First make a simple code that runs sequentially, for example loops ten times before stopping.
- Then make code that completes the same job quicker by running parallel.
To fix: connect the austin to NY
import time
import concurrent.futures
def do_work():
time.sleep(1) # Simulate some work with a delay
def sequential_execution():
start_time = time.time()
for i in range(10):
do_work()
end_time = time.time()
print(f"Sequential Execution Time: {end_time - start_time} seconds")
def parallel_execution():
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(do_work) for _ in range(10)]
concurrent.futures.wait(futures)
end_time = time.time()
print(f"Parallel Execution Time: {end_time - start_time} seconds")
# Run sequential execution
sequential_execution()
# Run parallel execution
parallel_execution()
Sequential Execution Time: 10.04626202583313 seconds
Parallel Execution Time: 1.0083749294281006 seconds